

성능 데이터모델
분석 및 설계 단계에서부터 성능과 관련한 데이터모델링을 수행하는 것입니다.
정규화, 반정규화, 테이블 분할/병합/추가, 칼럼 추가 , PK/FK 조정, 슈퍼타입/서브타입 조정들의 기능을 합니다
답은 1번입니다. 성능 데이터모델링은 '분석 및 설계 단계' 에서 진행하는 것이라 했습니다.
따라서 문제발생 시점은 틀린 말입니다.
나머지 2,3,4번은 맞는 말이므로 성능 데이터모델링의 특징이라 보면 되겠습니다.
2번은 당연한 말이고,
3번은 성능을 튜닝하면서 변경이 가능하다. <- 이 특징을 외워두면 되겠습니다.
4번 분석/설계 단계 얘기가 나오고 불필요한 처리비용을 줄이기 위한 방법이 성능 데이터모델링이라는 점에서 맞는 말이 됩니다



성능 데이터 모델링 순서 (빈출)
딱 잘라 말하겠습니다.
정규화 -> 용량산정 -> 트랜잭션 -> 반정규화 -> 기타 조정 이 5가지 키워드 절차에 따라 모델링이 이뤄집니다.
Q. 아래 설명을 읽고 다음에 들어갈 말은?
A. 데이터모델링을 할 때 정규화를 정확하게 수행한다.
B. 데이터베이스 용량산정을 수행한다.
C. 데이터베이스에 발생되는 트랜잭션의 유형을 파악한다.
D. 용량과 트랜잭션의 유형에 따라 ( ) 를 수행한다.
E. 이력모델의 조정, PK/FK의 조정, 슈퍼타입/서브타입 조정을 수행한다.
보시면 각 문장 별로 키워드가 있어요.
정규화 하구요 -> 용량산정 하구요. -> 트랜잭션 하네요. 다음은? 반정규화겠죠?





1번부터 봅시다. 정규화는 항상 조회 성능저하를 나타내므로, 반정규화 관점에서만 성능을 고려하여?? 아까 5가지 키워드 절차 말씀드렸을 때, 정,용,트,반,기 <- 이렇게 나왔었죠? 정규화를 가장 먼저 수행합니다. 따라서 1번은 틀렸어요.
2번은 용량산정은 트랜잭션을 위해 중요한 작업이 된다라는 말인데 맞습니다.
3번은 기타 조정에 대한 얘기네요. 중요한 절차죠.
4번도 기타 조정에 대한 얘기입니다. 맨 위에 성능 데이터모델링에 대한 기능 중 '칼럼 추가'를 쓴게 보이죠?? 맞는 말입니다.



정규화
정규화는 논리적 데이터모델링에 속하며,
Key/속성/관계에 대한 정의를 다루고 재사용성이 높다는 특징을 가진다고 했었습니다.
정규화를 통해 데이터의 입력/수정 등등을 할 때, 데이터들이 꼬이는 것을 막기 위해 분류작업을 하는게 목표입니다
1차 정규화?
1차 정규화는 모든 속성은 반드시 하나의 값만 가져야한다는 특징을 갖고 있습니다.
쉽게 말해서 '중복되는 속성을 제거'하는 작업입니다.

해당 사진처럼 중복/반복되는 속성을 분류해주는게 1차 정규화입니다.
2차 정규화?
2차 정규화는 모든 속성은 기본키에 종속되어야 하며, 일부만 종속되는 것도 안된다. 라는 특징입니다.
얘는 문제를 풀때보면 테이블이랑 '함수 종속성(FD)'가 같이 주어질텐데요.
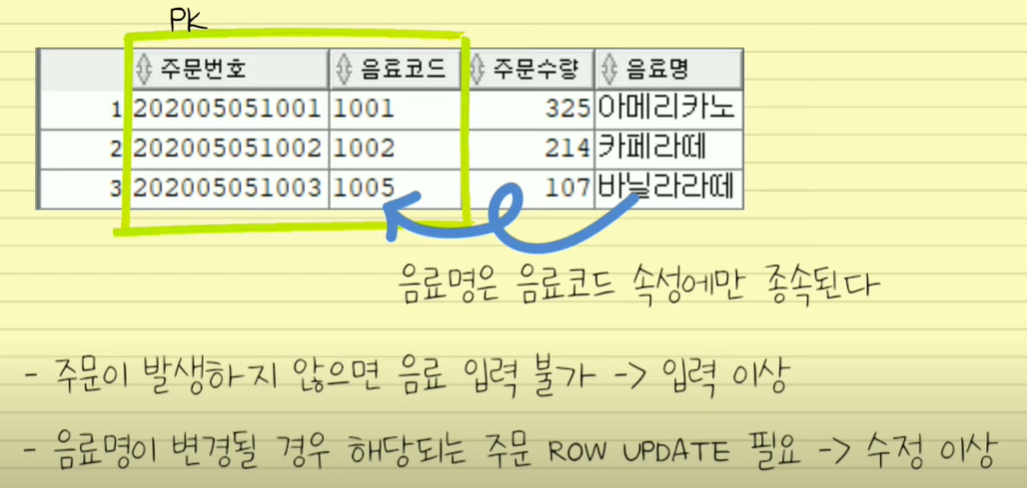
함수 종속성을 보면 PK(기본키)가 보일텐데요. 아래 사진을 봅시다.

얘는 관서번호, 납부자번호가 PK가 되고 이것에 종속된게 직급명, 통신번호입니다.
다른거로는 관서번호가 PK고 종속된건 관리점번호, 관서명, 상태, 관서등록일자입니다.
근데 테이블은 하나만 주어졌죠.
따라서 함수종속성에 따라 테이블을 2개로 나눠서 따라 작성하는게 2차 정규화입니다.






1차 정규화?
1차 정규화는 모든 속성은 반드시 하나의 값만 가져야한다는 특징을 갖고 있습니다. 쉽게 말해서 '중복되는 속성을 제거하는 작업입니다.'

해당 사진처럼 중복/반복되는 속성을 분류해주는게 1차 정규화입니다.

얘보면 X유형기능분류코드N 이런식으로 9개가 있습니다. 중복되는게 있죠? 이를 처리하는게 1차 정규화입니다.







반정규화
반정규화는 데이터를 중복하여 성능을 향상시키기 위한 기법입니다.
- 데이터 중복이요?
네, 데이터 중복은 사실 정규화 대상이긴 한데요.
반정규화에서는 일부러 데이터 중복을 추구합니다.
단순화를 위해서 중복,통합,분리 등을 수행하는 데이터 모델링 기법이기 떄문입니다.
- 중복칼럼 추가 : Join 감소를 위해 여러 테이블에 동일한 칼럼을 갖도록 함.
- 파생칼럼 추가 : 조회 성능을 우수하게 만들기 위해 미리 계산된 칼럼을 갖게 함.
- 이력테이블에 기능칼럼 추가 : 최신값을 처리하는 이력의 특성을 고려해서 칼럼을 추가. 이를 통해 최근 값을 찾기 위한 조회 성능 저하를 예방함.
- PK속성 추가
'Certification > SQLD 개발자' 카테고리의 다른 글
| [SQLD] 2 단원 51 - 60 번 문제 (0) | 2023.11.13 |
|---|---|
| [SQLD] 1단원 41-52문제 (0) | 2023.11.13 |
| [SQLD] 1단원 21-30문제 (0) | 2023.11.13 |
| [SQLD] 1단원 11-20 문제 (0) | 2023.11.13 |
| [SQLD] 1단원 1-10문제 (0) | 2023.11.13 |