
정답 : ③
SQL 1 : 500 + 100 + 30 + 10 + 5 = 645
count(*) 만 널 값을 포함한다.
SQL 2 : 10 + 5
IN ( null ) <-- null 속성 값을 가지는 tuple 추출할 수 없음.
SQL 3 : grade로 그룹화한다. null 또한 하나의 그룹으로 묶이므로 총 6개의 tuple이 생성된다.
COUNT(*) : NULL까지 포함
COUNT(표현식) : NULL 미포함

정답 : ②
광고매체ID별로 광고시작일자가 가장 빠른 데이터를 추출하는 SQL을 작성해야 한다.
MIN() 함수는 선택한 열의 가장 작은 값을 반환합니다 .

정답 : ④
3. GROUP BY로 그룹핑된 컬럼에 대해서 HAVING 조건절을 사용할 경우 집계된 칼럼의 FILTER조건으로 사용할 수 있다. 3번과 같은 쿼리의 경우 HAVING절대신 WHERE절을 이용해도 같은 결과를 낼 수 있다.
4. 중첩된 그룹함수의 경우 최종 결과값은 1건이 될 수 밖에 없기에
GROUP BY절에 기술된 메뉴ID와 사용유형코드는 SELECT절에 기술될 수 없다.
GROUP BY다음에 조건 설정(HAVING) 해주지 않으면 최종 결과건이 1개라 SELECT에 기술될 수 없다.
- GROUP BY는 출력값의 공통된 값을 묶어준다고 생각하면된다.
- GROUP BY에 사용된 컬럼에 조건을 부여할 수 있는 것이 HAVING절이다.
- 즉, GROUP BY에 적용된 컬럼에만 HAVING절을 적용할 수 있다. GROUP BY에 없는 컬럼에 HAVING 조건을 붙이면 오류가 발생한다.
- HAVING 조건절에는 그룹함수와 관련한 어떠한 조건을 붙일 수 있다

정답 : ②
SELECT MAX(가) AS 가, 나, SUM(다) AS 다
FROM A
GROUP BY 나
HAVING COUNT(*) > 1
ORDER BY 다 DESC;
해당 쿼리문은 다음과 같이 해석 가능하다.
- A테이블에서 가 컬럼의 가장 큰 값을 가 라고 한다.
- A테이블에서 나 컬럼을 선택한다.
- A테이블에서 다 컬럼의 값을 합한 것을 다 라고 한다.
- 해당 값에서 나컬럼으로 그룹화 한다.
- 그룹화 한 것에서 2개 이상의 값만 도출한다.
- 다를 기준 내림차순 정렬한다.

정답: 2번
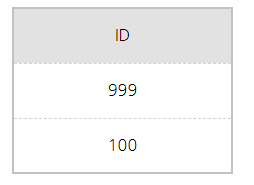
999, 100 순서로 나오는 SQL 결과
(CASE WHEN ID = 999 THEN 0 ELS ID END) 정답 999(첫번째행), 100(두번째행)
ORDER BY 절을 먼저 살펴보자.

CASE WHEN ~ THEN ~ END 의 CASE 절을 보니 SIMPLE_CASE_EXPRESSION 절이라고 확인할 수 있다.
위 CASE절을 만족하는 순서대로 정렬을 하게 된다.
ID로 그룹을 묶고 HAVING 조건에 의해서 100과 999의 칼럼만 남았다.
CASE절에 의해서 ID가 999이면 0이라고 하고 아니면 ID 그대로 둔다.

위의 표와 같은 형태로 바뀌지만 이는 ORDER BY절에만 적용되기 때문에
100과 0의 순서로 정렬을 하고서 SELECT 구문에 의해 데이터가 추출 될 때에는 원래의 데이터 그대로 나타난다.

정답 : 3번
ORDER BY절은 SELECT에 지정하지 않은 컬럼도 사용할 수 있지만,
GROUP BY절로 기준(범위?)가 묶여 있을 경우
GROUP BY 절에 기준이 되는 컬럼이거나
그룹 함수에 대한 컬럼이 아닌 컬럼이 ORDER BY절에 오면 오류가 발생한다.
2, 3번 모두 SELECT 절에 없는 '년' 컬럼으로 ORDER BY를 하고 있다.
2번은 행 전체 컬럼을 메모리에 로드하는 오라클의 특성 때문에 가능하다.
하지만 3번은 지역으로 GROUP BY를 하고 있기 때문에 각 지역당 존재하는 '년' 컬럼이 사라지게 된다. 따라서 불가능하다.
2번은 GROUP BY 가 없기 때문에 테이블열을 기준으로 실행됨.
GROUP BY 가 있으면 내부적으로 연산후에 데이터셋을 만든 것을 기준으로 하기 때문입니다.
서브쿼리도 마찬가지
3번 지문에서 ORDER BY는 순서상 마지막에 실행하고 SELECT 절에 있는 항목을 가지고 실행됨.
년 이라는 항목은 없으니 오류가 남

답: 3번
ORDER BY 절에 컬럼명 대신 Alias명이나 컬럼 순서를 나타내는 정수를 혼용하여 사용할 수 있다.
GROUP BY절을 사용하는 경우 ORDER BY 절에 집계함수를 사용할 수도 있다.
DBMS마다 NULL값에 대한 정렬 순서가 다를 수 있으므로 주의하여야 한다.

답: 2번
ORDER BY (CASE WHEN ID='A' THEN 1 ELSE 2 END), AMT DESCCASE절을 이용해서 원래의 정렬 순서를 변경하였다.
1-2 순(숫자 순)으로 배열이 되고,
그 이후는 AMT DESC 순서로 배열된다

답: 4번
SELECT 문장의 실행 순서는 FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY 이다.

답: 4번
승리건수가 높은 순으로 3위까지 출력하되 3위의 승리건수가 동일한 팀이 있다면 함께 출력하기 위한 코드
SELECT TOP(3) WITH TIES 팀명, 승리건수
'Certification > SQLD 개발자' 카테고리의 다른 글
| [SQLD] 2 단원 61 - 70 번 문제 (0) | 2023.11.13 |
|---|---|
| [SQLD] 1단원 41-52문제 (0) | 2023.11.13 |
| [SQLD] 1단원 31-40문제 (0) | 2023.11.13 |
| [SQLD] 1단원 21-30문제 (0) | 2023.11.13 |
| [SQLD] 1단원 11-20 문제 (0) | 2023.11.13 |